
Why the EDR Telemetry Project is Misleading

UPDATE - Author Response: The author of the EDR Telemetry Project responded, accusing me of spreading misinformation by saying his project was for detection, that it's always only ever been about telemetry.
The problem is, his own words contradict him. Nowhere does the site say the project isn't for detection, the creator gives detection as its primary use case in the screenshot below and he was the source of this claim. I didn't make it up, I pulled it from his own writing. Why he is stating this is beyond me.
The author himself as you can see in the below image describes that as the prime use case:

How can I be misleading when he’s the source of the claim? The tool is an EDR, which means Detection. If its telemetry isn't for detection, that should be stated however it isn't overtly outlined anywhere, but he suggests the opposite and that it can be used for detection as you can see in his own words.
It is disengenous to say Vendor A has something fully implemented, yet it can't be used while Vendor B might have a partial but they can actually use the data and if the author can't see that than I recommend he re-read this post. I am sorry but if you have to use a second telemetry tool, because your EDR doesn't let you use the telemetry it collects it is objectively not as "fully implemented" as one that does regardless of if it is used for detection or not.
He also noted that the definitions of what is considered "fully implemented" is well defined already and on the website. I asked if he could provide me a link to the specific details that each event need to meet at a minimum to get "fully implemented" that I would update the blog post to reflect it and was blocked. Well defined in my mind means having a list of minimum required fields so that it isn't ambiguous.
At the time of writing this, that does not exist, and if it does exist I will gladly update this post to reflect that.
Lastly, he mentioned that my comment about organizations using Sysmon to augment CrowdStrike for detection was anecdotal. He's right, it's an anecdote because I protect my clients' privacy. But let's be realistic: large enterprise detection teams are bigger than most MSSPs teams.
If you don't think they're building custom detections for things like DLL loads, you haven't worked at that level. We both agree an EDR isn't chosen on telemetry alone, which is precisely why so many organizations pick CrowdStrike for its core strengths and then augment it themselves with sysmon by choice.
I often see teams use Sysmon via a Splunk/Elastic forwarder to augment CrowdStrike with custom detections. The problem is that it's all detection, no response. We're looking at swapping the Elastic agent for LimaCharlie to fix that. They'd keep CrowdStrike as the primary EDR, but could finally use their custom Sysmon rules to actually kill a process or isolate a host (as well as for a number of other reasons.)
It should be noted at the time this was posted, at no point does the telemetry project state its not used for detection. It is unfortunate rather than take feedback/criticism and try and improve, that he resorts to personal attacks.
TL;DR: Make up your own mind. He admits people were confused enough about the project to ask him for clarification, yet somehow misses that their confusion is the entire reason I wrote this. It is also not lost on me, that he spent most of today telling me that the telemetry project was never about detection, while using that as the first and primary example.
He seems to not understand that if even he, the project creator doesn't understand how to use it, that people less experienced definitely won't. Hence the point of the post.
The irony speaks for itself.
"What's the best EDR?"
It’s a question that pops up constantly in security forums, but the truth is, there's no universal answer. The right tool depends entirely on your organization, your team's maturity, and your tech stack. Anyone telling you otherwise probably doesn't have your best interests at heart.
As someone who has built multiple SOCs and worked on highly mature detection engineering teams, I’ve run this evaluation playbook more times than I can count. It’s a grind, which is why I get the appeal of the EDR Telemetry Project. It seems like a great shortcut for comparing what vendors actually provide.
But there’s a problem. In its current form, the project is fundamentally misleading.
I've held off on writing this because it’s much easier to criticize than to build, and the project's intention is noble. The creator says its goal is to help users "build custom detection rules" by being transparent about telemetry.
The main goal of the EDR Telemetry project is to encourage EDR vendors to be more transparent about the telemetry they provide to their customers. Almost all EDR vendors have their detection rules hidden for many reasons, such as intellectual property protection and competitive advantage. However, we believe telemetry is slightly different, and vendors should be open about the raw telemetry their products can generate. When EDR vendors are open with their telemetry, users can better understand the data collected and use it to build custom detection rules tailored to their specific environments and security requirements.
In reality, the project’s scores have almost nothing to do with a tool's detection capabilities. The focus is only on what data is available for an analyst to investigate after an alert.
That distinction is critical, and it’s where the project can lead people astray. This is also precisely where the project loses its value as you will still have to do all the same testing prior to verify an event is actually usable.
What Does "Implemented" Actually Mean?
The EDR Telemetry Project's scoring system is based on three main categories: "Implemented," "Partially Implemented," and "Not Implemented". An event that is "fully" implemented receives the full weighted score for that feature.

The problem is, I can't find a clear definition for what "fully" or "partially" implemented actually means. This ambiguity is critical because it defines what the project can realistically be used for. In my mind, telemetry isn't fully implemented unless you can use it for both detection and response especially if the goal of the project is to help analyst understand the data to build custom detection rules.
This is why I was so shocked to see CrowdStrike in the number one spot. In the real world, it's common practice to supplement CrowdStrike with Sysmon for the specific purpose of getting better telemetry for custom detections. They've started to offer a service called Falcon Data Replicator (FDR) which exports the raw events so teams can actually use the telemetry, however it has an added cost and the events are definitely not structured in an easy to use way. Its one of the few EDR's that has to be supplemented for custom detection capabilities, so how could it possibly rank first? If I have to use two tools to get the same telemetry that doesn't feel very "fully implemented."
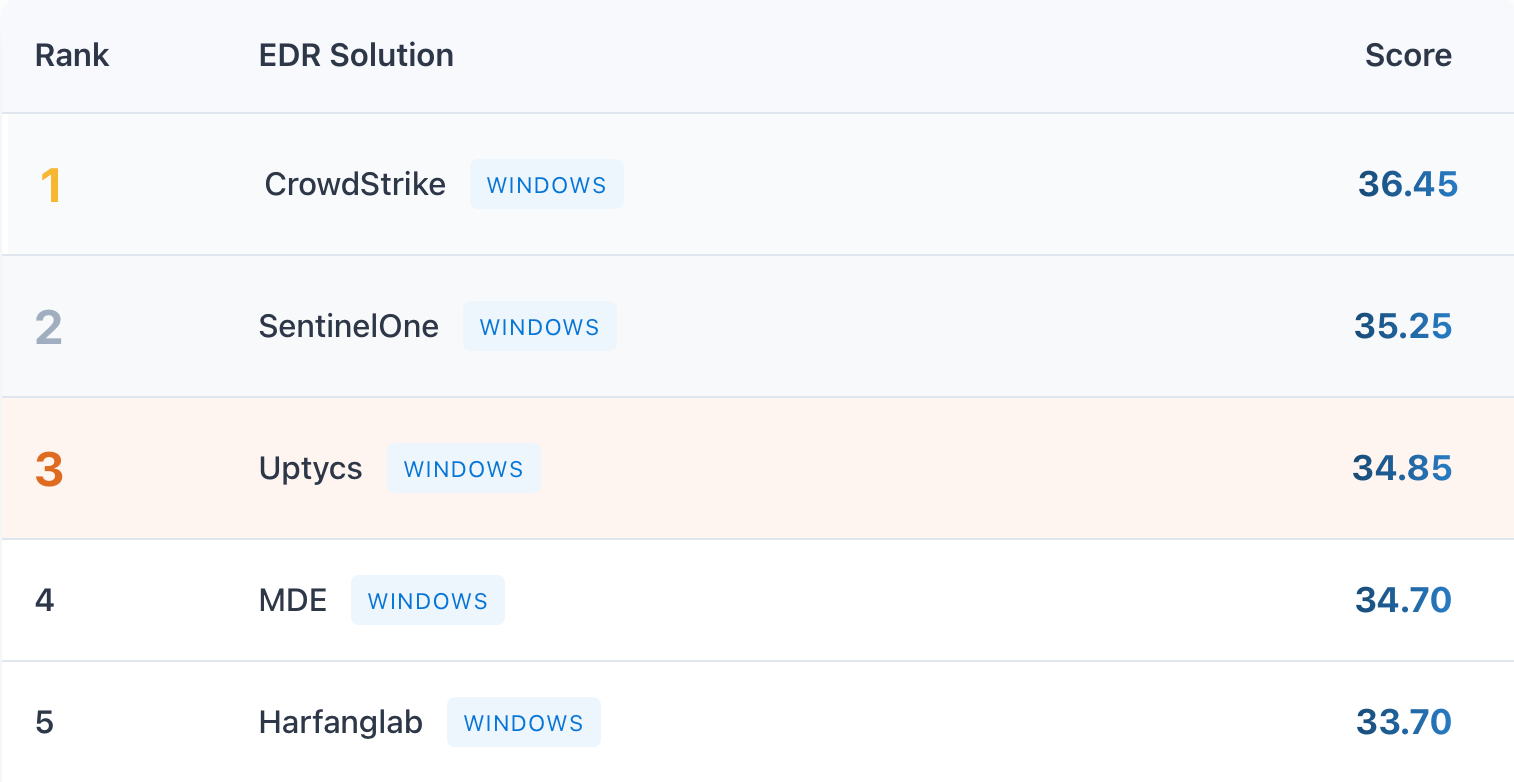
For those who don't know, CrowdStrike only lets you build custom detections on a handful of its event types. Most other EDR vendors collect similar data but actually make the telemetry available for writing rules. The ranking just felt backward. I mean CrowdStrike does technically have the events, but are they really fully "implemented" if I can't use them until after an incident has occurred?
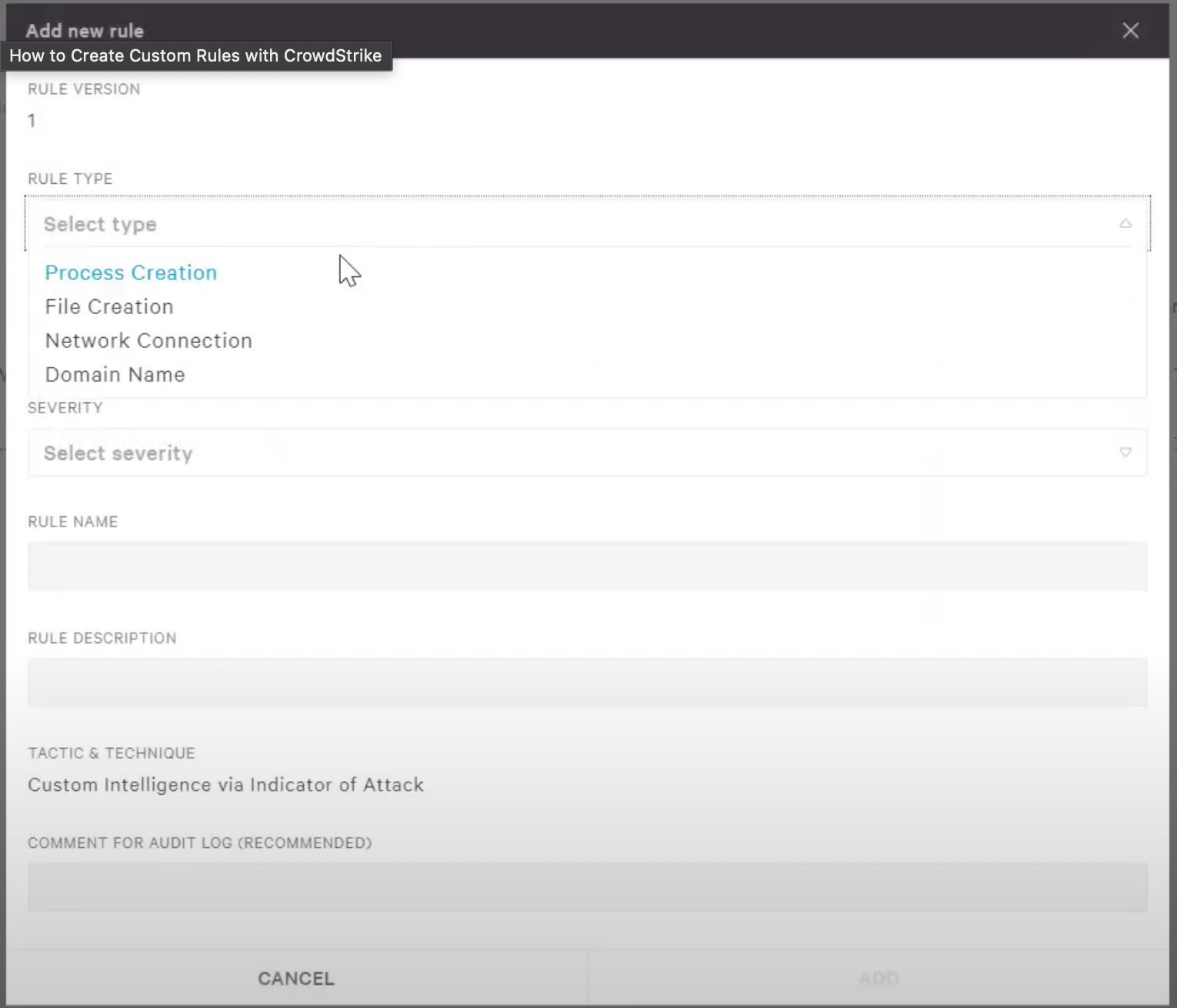
This isn’t a knock on CrowdStrike's quality as an EDR; I still consider it one of the best. Their philosophy is that they are the cybersecurity experts, freeing up your team to focus on other things. That’s a perfectly valid model. It just doesn't align with the project's stated goal of helping users "better understand the data collected and use it to build custom detection rules." A DLL load for example is marked as "fully implemented" by the project, but you can't actually write a custom rule on it in CrowdStrike.
From what I can tell, the project’s criteria for "fully implemented" seems to be this: Does the EDR produce the telemetry, and does it contain the expected metadata? Whether you can actually use that telemetry appears to be irrelevant to the score.
Putting the data to use and why there's no "best"
Every EDR solves problems in a different way. CrowdStrike, which the project ranks at #1, is a fantastic "batteries-included" solution. It’s arguably the best choice for an enterprise that wants to hand off endpoint security and doesn't plan on funding a dedicated detection engineering team. That said the batteries included philosophy doesn't lend itself to a high score for this project if you were to require the event to be useable to be fully implemented, and it'd likely score much much lower.
Then you have a tool like LimaCharlie, which sits down at #10. It represents the complete opposite philosophy: it’s a flexible platform built to give a skilled team the infrastructure they need to create a world-class detection program. While CrowdStrike intentionally limits what events you can build rules on, LimaCharlie’s approach is simple: if data exists on the endpoint, you can use it for a detection.
If the project's goal really is to measure telemetry for building custom rules, a tool like LimaCharlie should be a top contender. It allows you to:
- Ingest, alert on, and respond to raw Sysmon or Windows Event Logs and take action such as killing the processes based on the pids or isolating the host.
- Continuously collect endpoint artifacts using its native Velociraptor integration, which itself was only excluded because it required manual collection which LimaCharlie eliminated.
In fact, one of the reasons Velociraptor was excluded was that it relies on manual VQL queries for artifact collection.
This is the case for every single CrowdStrike event in the spreadsheet outside of the four they allow you to build custom detection on. Despite them being constantly streamed to the CrowdStrike console, they are only available retroactively or through manual queries. - Automatically store all unique binaries from your environment, letting you run YARA rules against a year's worth of executables.
- Scan memory and disk with YARA on a schedule, on-demand, or as an automated response.
These are native features, yet the project's opaque scoring system places this tool near the middle of the list. Where as CrowdStrikes design philosophy unintentionally would lower their rating, LimaCharlie's unintentionally should put them in the #1 spot, as technically you can enable the automated collection of all velociraptor artifacts. This seems to match the criteria here, as the extension doesn't have a cost to it and can be turned on:
Additional telemetry collection capability that can be enabled as part of the EDR product but is not ON by default.
Which gives the same weight as "implemented."
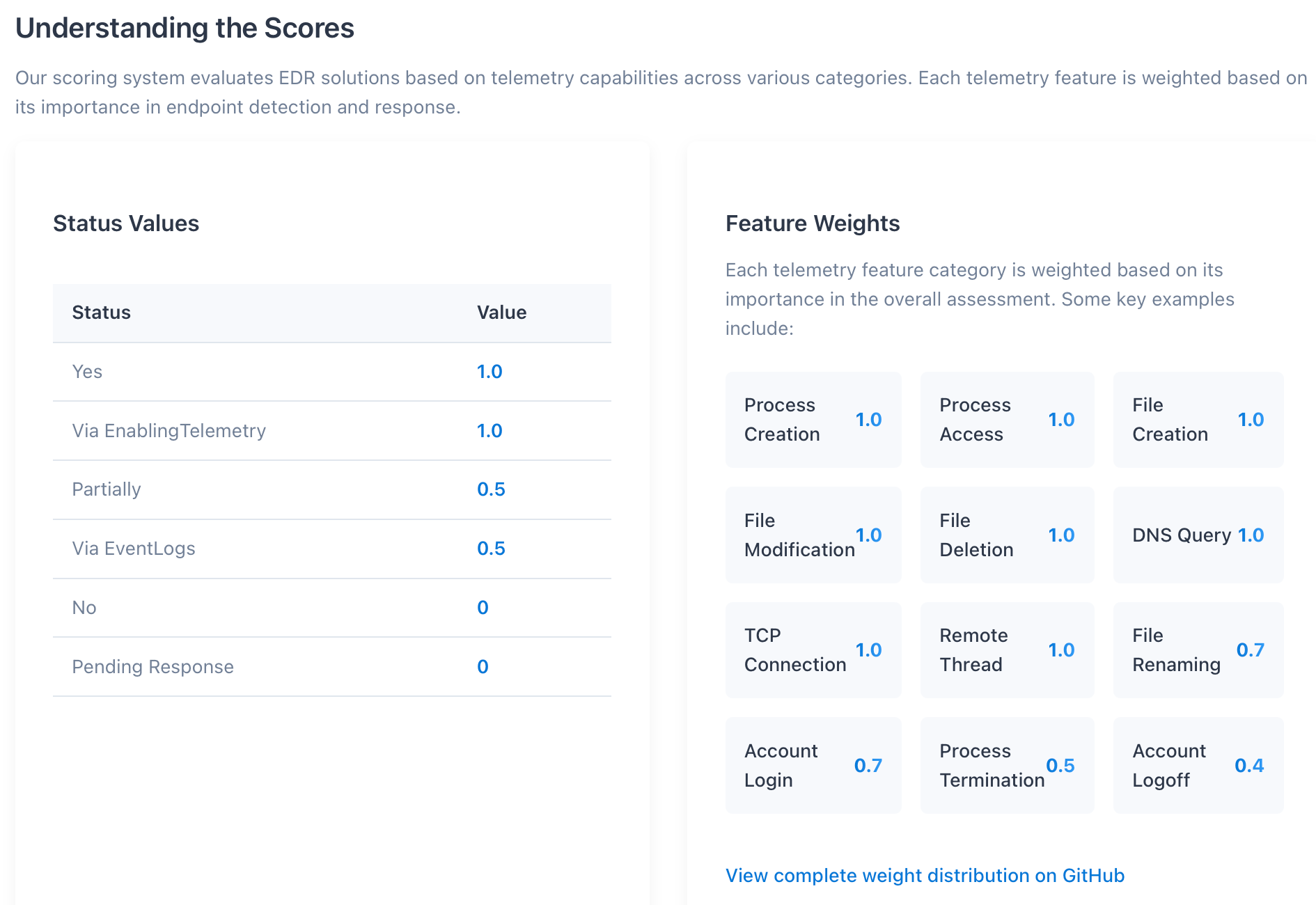
An Honest Measurement
The creator of the EDR Telemetry Project states:
However, telemetry is only one of the many attributes that make an EDR great; therefore, this project should not be used as a definitive method of comparing EDR products.
I completely agree. The problem is that in its current form, the project is deceptive and doesn't even accurately measure the one attribute it focuses on. Its scoring is based on opaque definitions that don't align with the real-world needs of a detection engineer evaluating the telemetry that's being collected. Taking detection completely out of the equation, telemetry that is useable is objectively more valuable than telemetry that isn't, and that is not measured by the project at all.
The core shortcoming is the ambiguous meaning of "implemented." The fix is straightforward: telemetry should only be considered
- Fully Implemented if its telemetry can be used for both Detection AND Response
- Fully Limited if its telemetry can be used for both Detection AND Response, but doesn't contain all the needed metadata to be useful on its own.
- Partial would be limited to Detection OR Response
- Partial limited where it's limited to either Detection OR Response while also not providing the full expected event metadata.
- Not implemented of course meaning it is unable to collect the event.
I would be genuinely curious to see the rankings if the project actually measured what it advertised. A tool like LimaCharlie would likely shoot to the number one spot based on pure telemetry collection and usability. But that wouldn't automatically make it the "best" EDR. For an organization without a detection engineering team, or one that is very junior, it would be nearly impossible to take advantage of it.
Likewise, if a vendor like CrowdStrike were to drop in these new, more honest rankings, it wouldn't mean it’s a bad product. It would simply provide a transparent view of the telemetry it makes available for custom rules, reflecting its specific product philosophy. It may even potentially drive CrowdStrike to open up the rest of the events for use making it a better product for everyone.
By making this change, the project could become the valuable resource it was intended to be, one that gives practitioners an honest, apples-to-apples comparison of telemetry they can actually use.
Already have an account? Sign in
No spam, no sharing to third party. Only you and me.