
"That Can be Evaded" and the Imperfect Detector

A common reason I see for not implementing a detection is that it can be evaded or is prone to false negatives. This isn't limited to beginners in the field; it's even implied, intentionally or not, in academic papers which might recommend against a technique due to its potential for false negatives, rather than making the more accurate point that you shouldn't rely on it in isolation.
This is an important distinction because everything can be evaded, and all detectors are prone to false negatives. But if we accept that no detector is perfect, we have to decide which flaw is worse: missing an attack, or drowning in noise?
The Base-Rate Fallacy: Why False Positives Matter More than False Negatives
In the context of creating detection logic, False Positives matter more than False Negatives. This isn't a new problem. A paper I was pointed to by Richard Bejtlich[1] written in 1999 by Stefan Axelsson, "The Base-Rate Fallacy and its Implications for the Difficulty of Intrusion Detection,"[2] laid this out perfectly. Axelsson highlighted a major flaw in how we often judge detection effectiveness using a statistical concept called the base-rate fallacy. In short, when you're looking for something incredibly rare (an actual intrusion) in a massive sea of benign activity, even an IDS that's 99% accurate will produce a staggering number of false alarms. The sheer volume of normal events means false positives will drown out the real alerts, making the system useless.
Axelsson argued that because of this, the false alarm rate is the true limiting factor for any IDS, not its ability to catch every attack. And while his paper focused on the IDS as a whole, this logic applies directly to the individual detectors we write. An IDS is just a collection of these detectors. If each one has even a small chance of firing incorrectly, the combined noise becomes overwhelming. A handful of poorly written, noisy detections can easily make an entire multi-million dollar security platform worthless.
Note: Your detection teams only opption to reduce false positives shouldn't be through tuning alone. Your detection teams should have their own SOAR access so they can purposefully write more broad detectors prone to false positives that only get presented to the end analyst after automated analysis determines it's worth sending.
The Times You Shouldn't Implement a Detector and When to Retire Them
I generally see three good reasons to avoid implementing a particular detection:
- It creates an unacceptable performance risk for the detection platform.
- It has a high false positive rate without an easy way to tune or allowlist alerts.
- The effort to create or maintain it is too high for the value it provides.
Beyond these reasons, it's usually just a prioritization issue. Detection priority is usually driven by internally and externally generated threat intelligence, which tells us what indicators of attack are actively being used against our industry. From there, we can use a framework like David Bianco's Pyramid of Pain[3]. It's the perfect guide for prioritizing our efforts, showing us which indicators will cause the most disruption to an adversary and where our time is best spent.

I apply the same logic to retiring atomic IOCs. The obvious exception is IP addresses, which churn constantly thanks to cloud and dynamic infrastructure. Everything else, typically leaving active forever unless it starts causing one of the problems mentioned above.
Overlapping Your Detectors
The concept of defense in depth applies to detection logic as well. Let's take the most recent article from TheDFIRReport - "From a Single Click: How Lunar Spider Enabled a Near Two-Month Intrusion"[4] and some activity they identified:
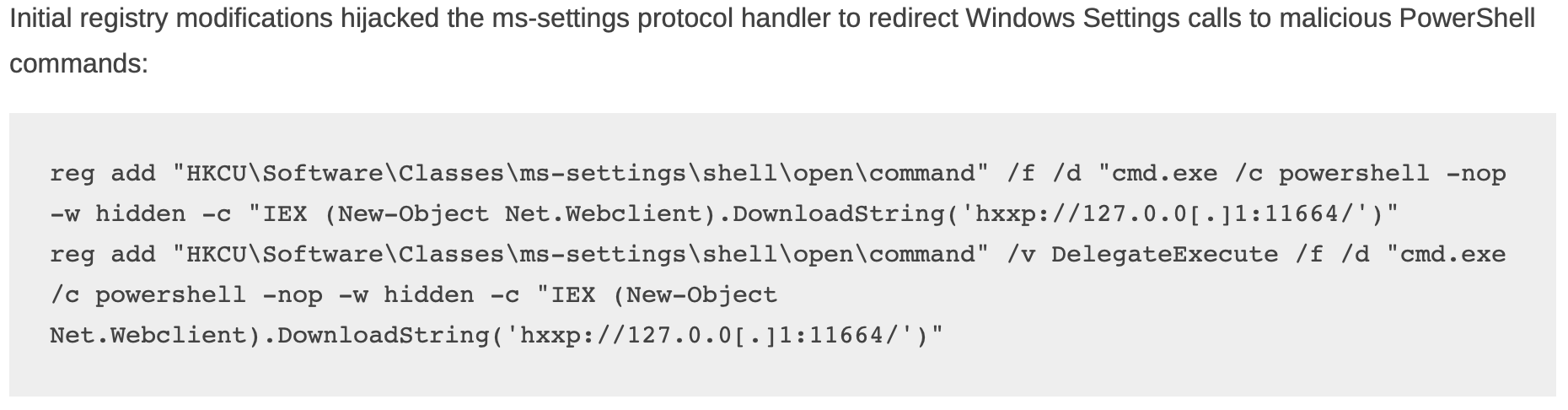
This image shows several distinct detection opportunities. Let's say in your environment, the only detector you had for this activity looked for iex or Invoke-Execution combined with DownloadString. This usually points to code being downloaded from the internet and executed, though here the request was just to localhost (127.0.0.1).
You shouldn't assume you're covered with just one alert. Instead, you should create other logic that overlaps with the first. For example, you could add a detector for the abuse of the ms-settings registry key or another that flags the use of DelegateExecute (a full list of detectors can be found at the bottom of TheDFIRReport[4:1]). A single malicious event should trigger multiple alerts, giving you overlapping coverage.
This is "detection in depth." If that first detector was overtuned or even filtered out localhost activity purposefully, it would have failed. By having multiple layers, you get more opportunities to catch the intrusion. I think of this as creating wide detectors: covering a single event with as many unique detections as possible. Then there are what I think of as tall detectors, which focus on how early or late in the kill chain you can detect the activity, but that's a topic for another day. Building this kind of coverage, however, often means embracing detections that aren't high-level TTPs.
When to Move Down the Pyramid of Pain
Now that we have the Pyramid of Pain as our guide, let's talk about when it makes sense to intentionally move down its levels. I recently covered the Catch-22 of Indicators of Compromise (IoCs) and how to maximize their value[5], explaining that we use them despite their limitations because no one wants to be breached by an indicator that was published weeks earlier. But there are other times it makes sense to work our way down the pyramid.
For instance, when you don't have the right log sources, or you have intel that a specific group is targeting you, focusing on the tools they use is a valid strategy. You might even explore novel ways to detect activity using existing logs while you wait for new data sources to come online. So what's the difference between a "behavioral/TTP" detector and a "tool" detector anyways?
A great example of detecting the tool MimiKatz, and not the behavior of credential dumping, is looking for the hard coded unique CLI patterns[6] it's known to use.
Similarly, if an adversary targeting your industry is using a tool like Sliver[7], you might decide your coverage is inadequate. This could lead you to explore options like TLSH fuzzy hashing or custom YARA rules, even though you know both can be evaded with simple, well-known methods like packers.
The Case for Imperfect Detectors
The reality is that every detection can be evaded. The key isn't whether a detector can be missed; it's whether it creates noise. As Axelsson's paper on the Base-Rate Fallacy showed, a high false positive rate is the fastest way to make a detection platform useless. This brings us to false negatives. When deciding whether to implement a new detector, their significance is tied directly to the level of effort involved.
If a low-fidelity IOC feed has almost no false positives and takes minutes to integrate, the value is obvious. However, a massive dataset of guaranteed malware hashes that crushes system memory for just a 0.11%[^8] chance of detection is a bad trade, even with zero false positives as it's now impacting your other more powerful detectors. An imperfect detector with an 80% chance of being missed is still a win if it has no false positives, requires little effort, and doesn't impact performance.
While we often focus on changing adversary behavior with high-level TTPs, the same effect can happen at the bottom of the pyramid. Forcing an attacker to recompile a tool to evade a simple hash or use new domains costs them time and resources. Better yet, the evasion techniques they're forced to adopt become detection opportunities in their own right. The goal isn't to be perfect; it's to be a difficult target. Each layer, no matter how simple, forces the adversary to adapt, and that's a win.
Sources
Already have an account? Sign in
No spam, no sharing to third party. Only you and me.